







Перевод статьи о разработках Facebook в области самообучающегося искусственного интеллекта, о том, как современный ИИ способен понимать содержание видео без маркированных данных обучения!
Как написал Артем Кравченко, если Facebook в ближайшее время внедрит этот инструмент в модерацию, арбиражникам придется не сладко.
Что представляет собой настоящее исследование
Один из отличительных признаков человеческого познания – это наша способность многое узнавать из окружающего мира без наличия фактического обучения. Дети, например, учатся говорить вне зависимости от того, есть ли у нас словари или нормы произношения. В качестве важного этапа нашей работы в отношении эмуляции данной способности в системах искусственного интеллекта представлена новая система, которой мы здесь делимся. Она названа «Generalized Data Transformations» (или «Система Обобщенного Преобразования Данных»). Она демонстрирует беспрецедентную эффективность в понимании содержания видеоматериалов, при этом не используя маркированные данные обучения.
Система «Generalized Data Transformations» предоставляет нам систематический способ надежного изучения взаимосвязи между аудио- и визуальной информацией для познания этого мира и его структуры. Это дает возможность достигать рекордной эффективности, когда мы настраиваем модель под конкретные последующие задачи. Такой способ устанавливает новые стандарты для сферы распознавания действий в видеоматериалах, поиска информации, техники обучения в несколько кадров и классификации аудио.
Поскольку система является самоконтролируемой и не опирается на наличие маркированных примеров, этот подход значительно увеличивает наши возможности для построения систем искусственного интеллекта, которые могут получать знания о мире из большого количества видео, а не только из маленькой подгруппы, маркированной комментаторами из числа людей вручную.
Как это работает
Многие предыдущие исследования по вопросу самоконтролируемого обучения были сфокусированы на том, чтобы установить информативные суррогатные (или предложные) задачи для обучения нейронных сетей. Эти задачи используют некоторые характерные свойства данных в качестве контрольного сигнала. Например, система может использовать цвет изображения как контрольный параметр и научиться раскрашивать черно-белые картинки. Изучая соответствующие цвета каждого предмета (или объекта), система косвенным образом распознает свойства этого предмета (или объекта), которые также в дальнейшем будут соответствовать другим задачам. Похожим образом исследователи могут использовать будущие фрагменты видео для того, чтобы обучить систему предварительно определять пиксели в следующем кадре.
Методы контрастного шума обучают системы за счет создания как семантически значимых изменений (таких как, например, загрузка изображения кошки вместо собаки), так и изменений, которые модифицируют входные данные, но не меняют их семантику (например, обрезка видео или добавление фильтра), по отношению к конкретному видео. Этот способ затем ограничивает полученное представление до инвариантного в отношении незначительных преобразований и делает его чувствительным по отношению к существенным изменениям. Это приводит к надежному и эффективному обучению. Однако предыдущие попытки применения данного метода, как правило, были эффективны только для ограниченного круга (семейства) предложных задач.
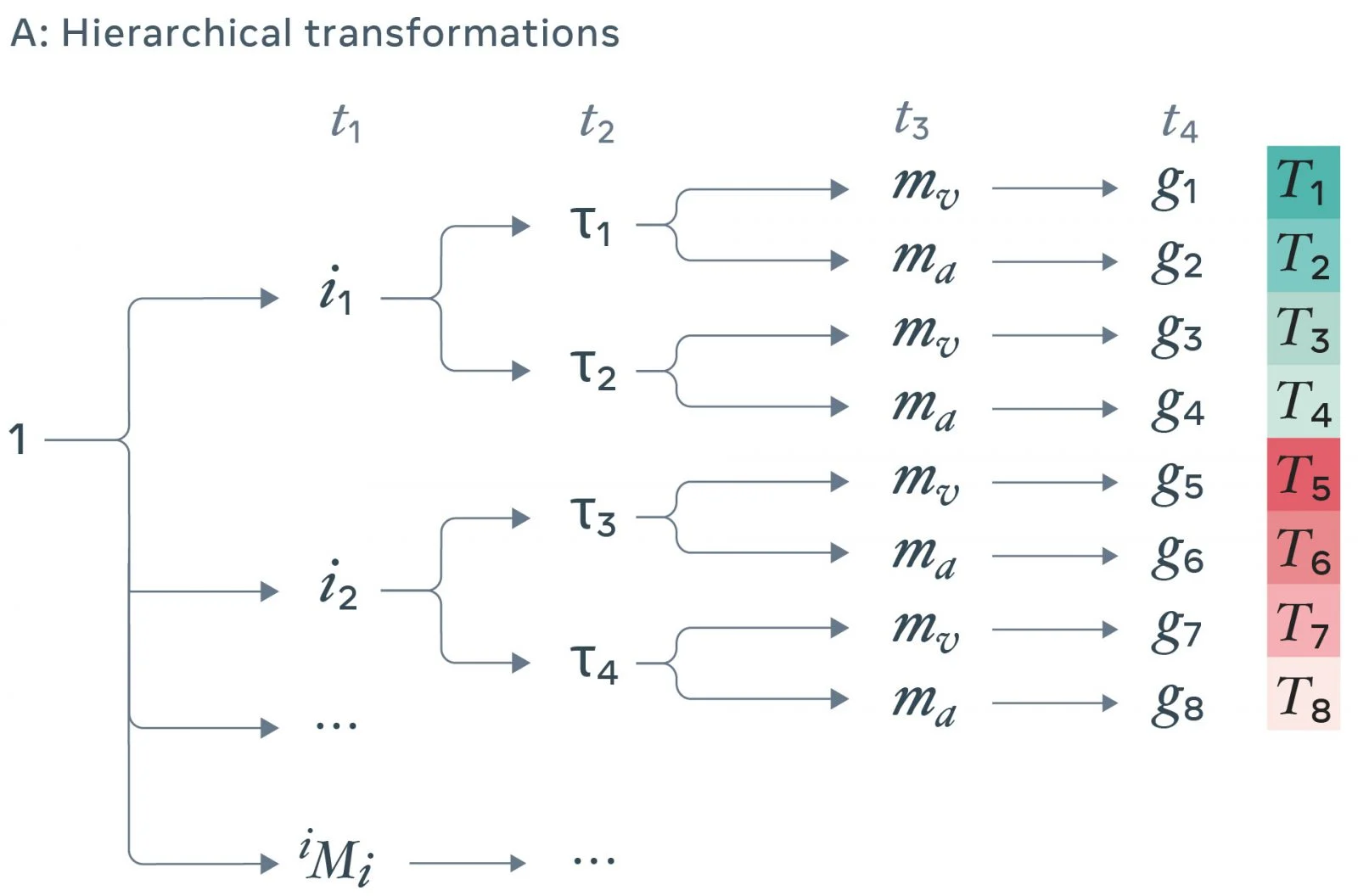
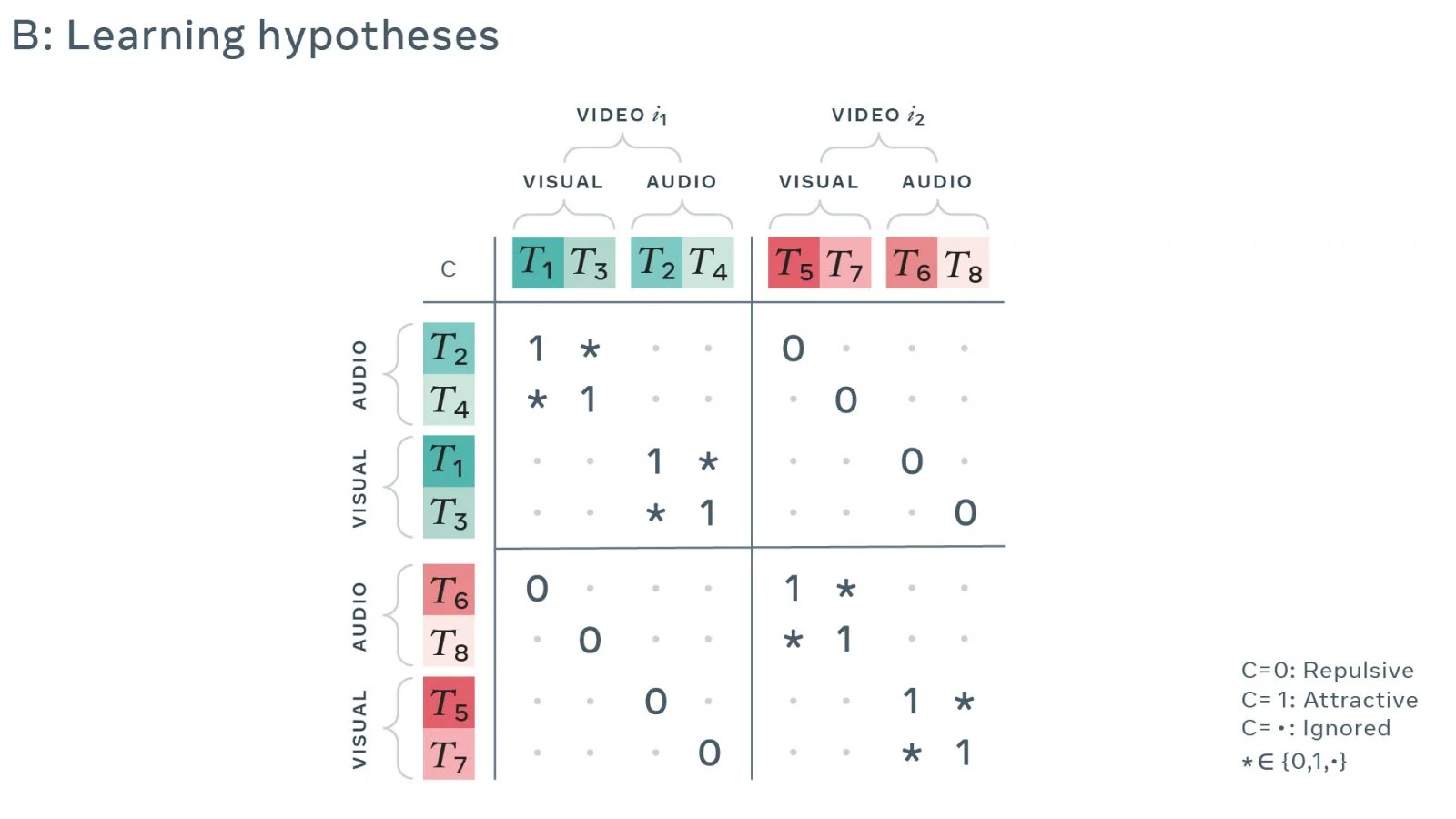
В нашей работе представлена система (структура), которая значительно расширяет степень выраженности шум-контрастных формулировок для предложных задач и демонстрирует эффективность за счет изучения мультимодальных данных. Наше исследование сфокусировано на перекрестном модальном контроле: вместо использования одиночной модальности, мы получаем знания за счет наличия взаимосвязей между звуком и изображениями в видеоматериалах. В нашей системе для создания серии преобразований данных используется иерархическая схема выборки (как показано ниже на рисунке A). Затем определяется матрица контрастности для уточнения того, из каких пар преобразований данных должно производиться обучение модели в отношении инвариантности или отличительности (как видно ниже на рисунке B). В конечном счете, мы используем потери контрастности шума, чтобы изучить объединенное пространство для встраивания аудио- и визуального рядов, в котором пары преобразований либо собираются вместе, либо разделяются. Для обучения аудиовизуальным представлениям, мы разрабатываем такие модели, которые являются инвариантными по отношению к модальности, но отличительными по отношению к образцу. Чтобы сделать все это функционирующим, мы используем «изогнутые» нейронные сети для кодирования фрагментов аудио и изображений в многомерные векторы. Параметры кодировщиков оптимизируются таким образом, что представления соответствующих друг другу по времени фрагментов аудио и изображений расположены рядом в векторном пространстве (как изображено ниже на рисунке C). И наоборот, кодирование фрагментов аудио и изображений, которые не имеют друг с другом ничего общего, производится так, что они разделяются.
A: Иерархические преобразования
B: Изучение гипотез
C: иллюстрация

Мы показываем, что многие прошлые исследования по вопросам самоконтролируемых и перекрестных модальных систем могут быть сведены к конкретным примерам в рамках комплексной системы «Generalized Data Transforms».
Почему это важно
Для создания по-настоящему умных, интеллектуальных машин, мы должны дать им возможность получать знания непосредственно из окружающего мира, без необходимости четкого руководства на каждом этапе. Способность изучать мир за счет его видов и звуков по мере их появления, без явного контроля – отличительная черта такого типа обучения. И напротив, область исследования искусственного интеллекта, со времени ее появления, полагалась на людей, маркирующих огромные объемы данных. В Facebook, как и во всем сообществе, занимающимся исследованием искусственного интеллекта, замена контролируемого обучения с ограниченными данными другим видом – самоконтролируемым обучением, с неограниченными данными – считается, пожалуй, самым важным рубежом в этой сфере. Наша работа соответствует современному уровню достижений в этой области и находит широкое применение, как в исследовательских, так и в практических работах. Сюда включено все – от обнаружения неприемлемого контента, например, агрессивных высказываний или домогательств в видео, до выработки более точных персонализированных рекомендаций по отношению к видеоматериалу и улучшения условий работы пользователя в виртуальной реальности.
Полная статья на английском: https://arxiv.org/pdf/2003.04298.pdf